Elastic Stack(Elasticsearch, Logstash, Kibana and Beats)
들어가면서
- RDMS에서의 데이터 검색은 보통 like와 같은 형식으로 SQL로 데이터 검색이 이루어집니다. FULL TEXT SEARCH(MATCH, AGAINST)의 사용은 MySQL에서만 사용이 가능하며 MySQL 5.7이후로 지원합니다. 데이터가 많아지는 시점에서의 좋은 대안이 될 수 있는 Elasticsearch에 대해 학습하고 실습에 적용해보고자 합니다.
Elastic Stack
-
기존 ELK Stack(Elasticsearch, Logstash, Kibana)에서 Beats가 추가되면서 Elastic Stack으로 변경
-
Components
- Beats : 데이터를 전송하는 경량 데이터 수집 플랫폼
- Elasticsearch : JSON 기반의 분산형 검색 및 분석 엔진으로 대규모 데이터를 손쉽게 저장, 검색, 분석
- Logstash : 동적 데이터 수집 파이프라인을 제공하는 확장형 플러그인
- Kibana : 데이터의 구체적 분석, 시각화를 제공하는 확장형 사용자 인터페이스
-
FlowChart
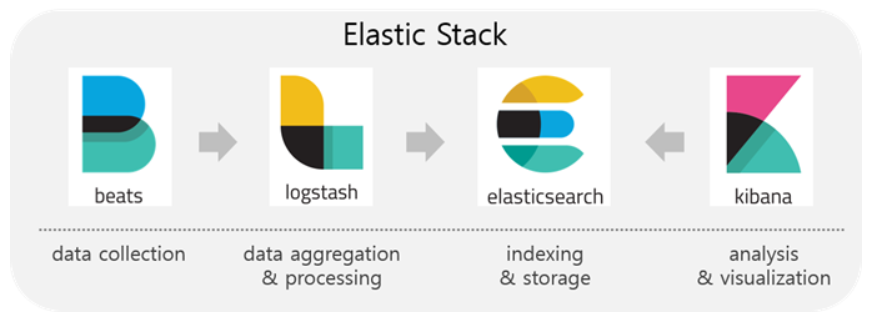
- 1개 이상의 수집할 데이터가 발생 서버에서 Beats가 Logstash로 Data를 전송한다.(각 Client 서버마다 Beats가 설치되어 있어야 한다)
- Logstash로 전달된 Data를 필터를 통해 가공하여 Elasticsearch로 전달한다.(Optional)
- Elasticsearch로 전달 받은 데이터를 서버(Elasticsearch)에 저장한다.
- Kibana에서 Elasticsearch에 저장된 데이터를 토대로 분석을 통해 시각화된 자료를 제공한다.
- 1개 이상의 수집할 데이터가 발생 서버에서 Beats가 Logstash로 Data를 전송한다.(각 Client 서버마다 Beats가 설치되어 있어야 한다)
-
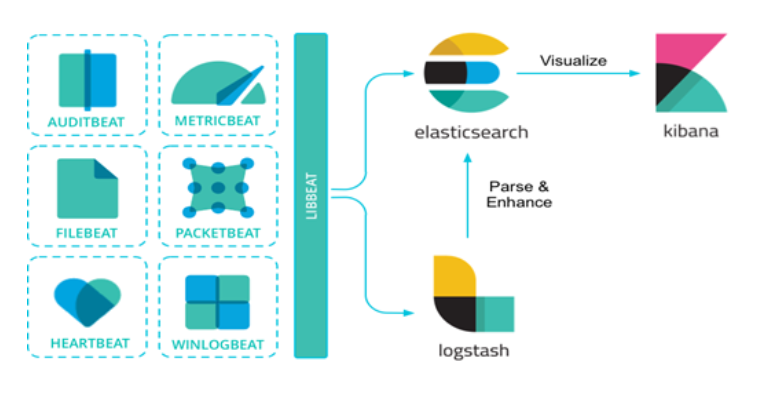
Architecture
-
Architecture With Buffering
- 데이터를 안정적으로 버퍼링하고 전달하는 Redis, Kafka, RabbitMQ랑 같이 사용 가능
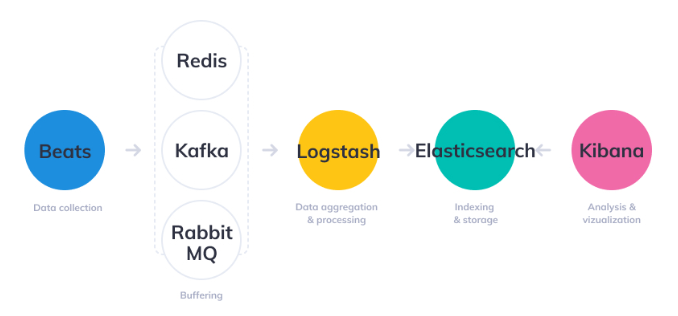
Beats
- 데이터를 수집하는 원격서버에 Agent 형식으로 설치하는 오픈소스 데이터 수집기
- 다소 부피가 큰 Logstash의 기능을 세분화
- 수집된 데이터 전송 경로
- Elasticsearch에 직접 전송
- Logstash를 통해서 전송
-
아래와 같은 다양한 데이터 수집 환경에 맞는 beats를 선택하여 설치할 수 있고 libbeat라는 직접 개발 가능한 라이브러리를 제공한다.

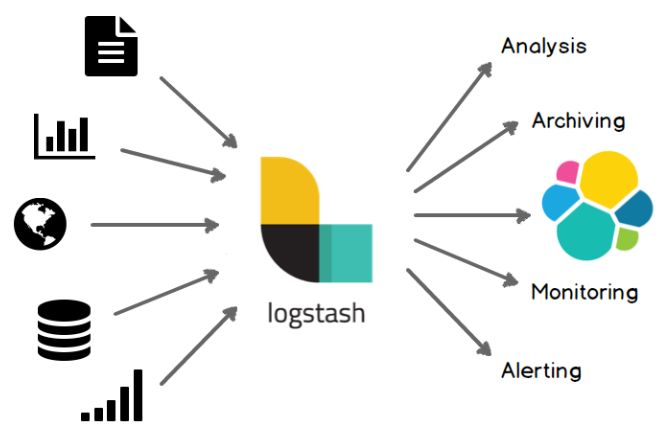
Logstash
- 실시간 파이프라인 기능을 가진 오픈소스 데이터 수집 엔진
- 서로 다른 데이터를 탄력적으로 통합하고 사용자가 선택한 목적지로 데이터를 정규화 가능
-
INPUTS, FILTERS, OUTPUTS 파이프라인을 통해 원하는 형식으로 가공 및 변환 후 가공된 데이터를 Elasticsearch로 전달한다.
-
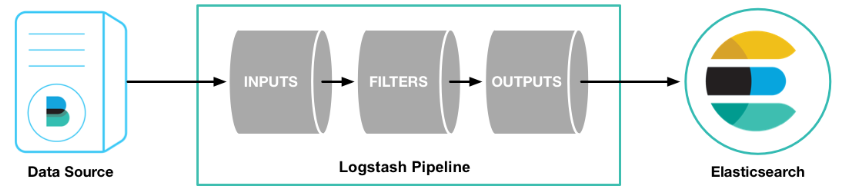
PipLine
- INPUTS, FILTERS, OUTPUTS로 구성
- INPUTS : Beats로부터 데이터를 받을 기본 설정(ports, host, timeout)
- FILTERS : Elasticsearch에 전달하기 전에 원하는 데이터의 타입, 형태 등으로 필터링/전처리
- OUTPUTS : Beats로부터 받아 전처리한 데이터를 전송할 곳을 지정
- INPUTS, OUTPUTS는 필수적이며 파싱 여부에 따라 FILTERS는 선택적으로 사용 가능하다.
- INPUTS, FILTERS, OUTPUTS로 구성
Kibana
- Elasticsearch에서 저장된 데이터를 쉽게 시각화 하고 탐색할 수 있는 웹 인터페이스를 제공
-
사용자가 Elasticsearch에 쿼리를 실행하고 결과를 다양한 형태로 시각화 하여 분석할 수 있도록 도와준다.
-
Role
- 데이터 분석과 시각화 툴 오픈소스 기반의 데이터 탐색 및 시각화 도구 제공
- Elastic 관리 보안, 스냅샷, 인덱스 관리, 개발자 도구 등 제공
- Elastic 중앙 허브 모니터링을 비롯해 엘라스틱 솔루션을 탐색하기 위한 포털
-
Visualize
- Discover : 데이터를 확인하고 탐색하기 위한 기능
- Visualize : 엘라스틱 서치에 저장된 데이터를 그래프나 표, 지도 등 다양한 타입으로 보여주는 기능
- Dashboard : 시각화 타입들을 한 페이지에 모아 볼 수 있는 기능
- Canvas : 인포그래픽 형태로 데이터를 프레젠테이션할 수 있게 해주는 툴
- Maps : 위치정보가 포함된 데이터를 지도에 올려 시각화 할 수 있는 기능
Elasticsearch
- Apache Lucene 기반의 Java 오픈소스 분산 검색 엔진
-
Elasticsearch는 단독 검색을 위해 사용하거나 Elastic Stack을 기반으로 사용한다.
-
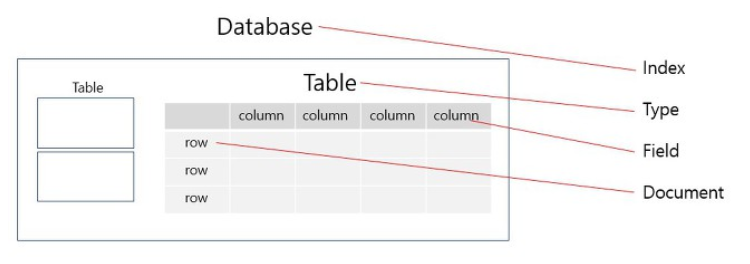
Structure with RDB
- RDB
- 데이터를 행렬(Column, Row) 데이터로 저장하는 방식
- Elasticsearch
- JSON Document로 직렬화된 자료 구조를 저장하는 방식
- RDB
-
Inverted Index
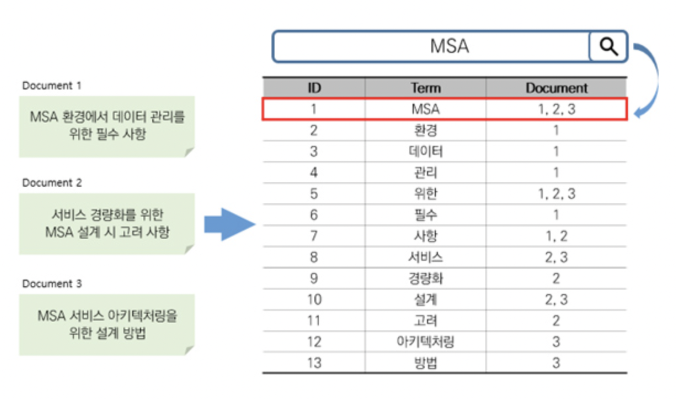
- Elasticsearch는 역색인(Inverted Index) 자료 구조를 사용(Full Text Search에서 빠른 성능을 보장)
- RDB
- 데이터 수정, 삭제의 편의성과 속도면에서 좋지만 특정 단어 검색 시 ROW 개수만큼 확인을 반복(Full Scan)
- Elastcsearch
- 특정 단어가 어디에 저장되어 있는지 알고 있어서 모든 Document의 검색이 필요 없음
-
RESTful API
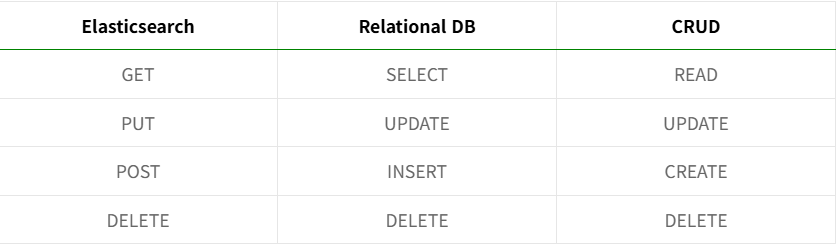
- 데이터를 CRUD하기 위해 RESTful API 방식을 사용
-
Components
- Cluster
- 전체 데이터를 저장하고 모든 Node를 포괄하는 통합 색인화 및 검색 기능을 제공
- 동일한 Cluster 이름을 서로 다른 환경에서 사용하면 안됨(dev, stage, prod)
- Cluster에 최소 하나 이상 노드의 집합으로 존재하고 독립적인 Cluster를 여러개 둘 수 있다
- 서로 다른 Cluster는 데이터의 접근, 교환을 할 수 없다
- Node
- Cluster에 포함된 단일 서버
- 데이터를 저장, Cluster의 색인화 및 검색 기능에 참여
- 임의 UUID가 지정되거나 특정 이름으로 정의가 가능
- 다양한 역할로 분류
- 대규모 Cluster에서 Load Balancing 역할을 하는 Node
- 색인된 데이터 CRUD Node
- 전처리 파이프라인 Node
- 전체 Cluster를 제어하는 Master Node
- Shard
- 데이터를 분산해서 저장하는 방식
- Scale-out할 경우 Index를 여러 Shard로 쪼갠다
- 최소 1개가 존재하며 검색 향상을 위해 Cluster의 Shard의 개수를 조정할 수 있다
- Replica
- 다른 형태의 Shard
- Node 손실 경우를 대비해서 데이터의 신뢰성을 위해 Shard를 복제하는 방식
- Replica는 서로 다른 Node에 위치하는 것을 권장
- Index
- Index는 여러 개의 Shard로 분할할 수 있다
- 하나의 Index는 복제하지 않거나 1회이상 복제할 수 있다
- 복제된 Index는 기본 Shard(복제 원본 Shard), Replica Shard(기본 Shard 복사본)을 갖는다
- Index 생성 후 Replica 수는 변경 가능하지만 Shard 수는 변경이 불가능하다
- Type
- Index에서 하나 이상의 Type을 정의할 수 있다
- Document
- Index화 할 수 있는 기본 정보 단위
- Cluster
-
Pros & Cons
- Pros
- 대량의 비정형 데이터 보관 및 검색 가능(Schemaless)
- Full Text Search(Inverted-Index)
- RESTfUL API
- 확장성과 가용성(Shard)
- Cons
- 실시간 처리가 불가능(Near Real Time): 색인된 데이터가 내부적으로 Commit과 Flush 과정을 거쳐야 함
- Transaction Rollback 기능을 제공하지 않음 :데이터 관리에 유의가 필요
- 실질적인 Update를 지원하지 않음 : 실제로 데이터 수정이 아닌 삭제 후 생성 과정으로 이루어짐
- Pros
Reference
- https://idkim97.github.io/2024-04-22-ELK(Elasticsearch+LogStash+Kibana)%20%EC%8A%A4%ED%83%9D%EC%9D%B4%EB%9E%80/#-elk-%EC%8A%A4%ED%83%9D%EC%9D%B4%EB%9E%80-
- https://medium.com/day34/elk-stack%EC%9D%84-%EC%9D%B4%EC%9A%A9%ED%95%9C-%EB%A1%9C%EA%B7%B8-%EA%B4%80%EC%A0%9C-%EC%8B%9C%EC%8A%A4%ED%85%9C-%EB%A7%8C%EB%93%A4%EA%B8%B0-ca199502beab
- https://kim-dragon.tistory.com/20
- https://velog.io/@shawnhansh/AWS-RDSmySql-%ED%94%84%EB%A6%AC%ED%8B%B0%EC%96%B4-%EC%83%9D%EC%84%B1%ED%95%98%EA%B8%B0
- https://soyoung-new-challenge.tistory.com/58
- https://choseongho93.tistory.com/entry/Elasticsearch%EB%9E%80-%EA%B0%9C%EB%85%90-%EB%B0%8F-%EC%A2%85%EB%A5%98-RDBMS%EC%99%80-%EC%B0%A8%EC%9D%B4
- https://idkim97.github.io/2024-04-19-Kibana(%ED%82%A4%EB%B0%94%EB%82%98)%EB%9E%80/
- https://tecoble.techcourse.co.kr/post/2021-10-19-elasticsearch/
- https://choseongho93.tistory.com/entry/Elasticsearch%EB%9E%80-%EA%B0%9C%EB%85%90-%EB%B0%8F-%EC%A2%85%EB%A5%98-RDBMS%EC%99%80-%EC%B0%A8%EC%9D%B4