Clustered Index and Non-Clustered Index
0. 들어가면서
Indexes are a powerful tool used in the background of a database to speed up querying. Indexes power queries by providing a method to quickly lookup the requested data. Simply put, an index is a pointer to data in a table. An index in a database is very similar to an index in the back of a book.
인덱스는 데이터베이스 백그라운드에서 쿼리 속도를 높이는 데 사용되는 강력한 도구입니다. 인덱스는 요청한 데이터를 빠르게 조회할 수 있는 방법을 제공하여 쿼리에 힘을 실어줍니다. 간단히 말해, 인덱스는 표의 데이터에 대한 포인터입니다. 데이터베이스의 인덱스는 책 뒷면의 인덱스와 매우 유사합니다.
- Page
- 데이터 파일을 구성하는 구성 단위
- SQL Server의 기본 데이터 저장 단위(8KB)
- 데이터를 READ/WRITE하는 행위는 모두 페이지에 기록/읽어짐
- Heap
- 정렬의 기준이 없이 저장된 Table의 형태
- Clustered Index가 없는 테이블
- Table
- Heap or Clustered Index
- 상황에 맞게 Heap을 사용할지 Clustered Index를 사용할지 선택
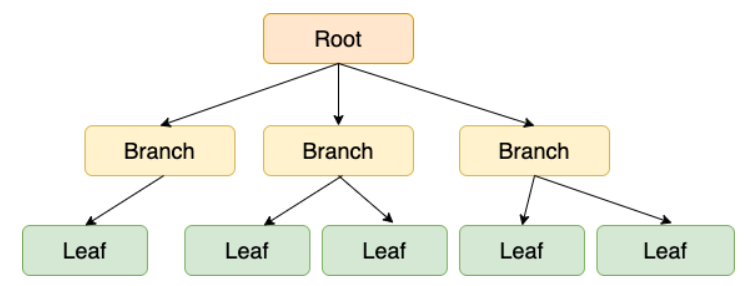
Balanced Tree
- Root Node(상단), Branch Node(중간), Leaf Node(하단)로 구성
-
하나의 node에 여러 개의 data를 저장한다.
-
1. B-Tree(Balanced Tree)
- 데이터가 정렬된 상태로 유지된다.
- 어떤 값에 대해서도 같은 시간에 결과를 얻을 수 있다.(균일성)
- Internal, Branch node에 key와 data를 담을 수 있다.
- 모든 node를 탐색한다.
- INSERT/UPDATE/DELETE의 반복이 잦으면 성능이 악화된다(정렬).
- DBMS는 B-tree의 인덱싱을 활용해 특정 데이터를 찾기 위한 Read 작업의 빈도를 낮춥니다.
-
2. B+Tree
- B-Tree의 확장 개념으로 MySQL의 InnoDB는 B+Tree 구조로 되어 있다.
- B+Tree의 Leaf node
- 모든 Leaf node들은 LinkedList 형태로 이어져 있다.
- 실제 데이터는 Leaf Node에만 저장되고 Internal node들은 key만 가지고 올바른 Leaf node로 연결해주는 라우팅 기능을한다.
- Leaf node에 key, data를 담을 수 있다.
- 중복 키가 존재하며 한 node당 key를 많이 담을 수 있다.(트리의 높이가 낮음)
- Leaf node에서 선형 탐색을 한다.
Index
- 데이터 검색 성능의 향상을 위해 테이블 열에 사용하는 자료구조
-
단일/여러 개의 Column을 이용하여 인덱스 생성이 가능하다.
-
1. Pros & Cons
- Query 부하가 감소하여 시스템 전체 성능이 높아진다.
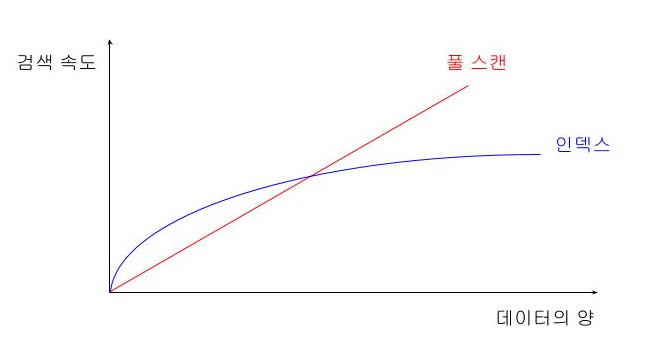
- 인덱스 사용 시 Full Scan 없이 빠르게 검색할 수 있다.
- 인덱스가 없으면 데이터를 찾기 위해 테이블 전체를 Full Scan하게 되어 검색 속도가 매우 느려진다.
- 인덱스는 테이블 크기의 10% 내외의 공간을 추가로 사용한다.(사용하지 않는 인덱스는 제거해야 한다.)
- Select Query가 아닌 INSERT/DELETE/UPDATE 작업이 자주 일어나지 않는 Column에 인덱스를 사용하는 것이 좋다.
- DBMS는 항상최신 정렬 상태로 인덱스를 유지해야 원하는 값을 빠르게 탐색할 수 있다.
- INSERT/DELETE/UPDATE 가 계속 수행되면 계속 정렬을 해야 해서 부하가 발생한다.
- 부하 최소화를 위해 인덱스를 사용하지 않음 처리를 한다.
-
2. Correlation
-
3. Column
- INSERT/DELETE/UPDATE 가 빈번하게 일어나지 않는 Column
- Join, Where, Order by와 같은 조건문이 자주 사용되는 Column
- 데이터 중복이 없는 Column
-
4. Category
- Clustered Index : 인덱스와 데이터를 함께 관리한다.
- Non-Clustered Index : 인덱스에 대한 정보를 따로 관리한다.
-
5. Search
- Index Scan : 해당 테이블의 Column을 모두 찾는다.
- Index Seek : 해당 Index를 바로 찾아간다.
Clustered Index
-
1. Features
- B-Tree 구조를 가지는 가장 일반적인 인덱스
- 실제 테이블 데이터가 항상 정렬된 상태를 유지하고 있고 인덱스에 실제 데이터를 저장하고 있다.
- 가장 적합한 Column 하나만을 Clustered Index로 지정한다.
- 테이블당 하나의 Clustered Index 존재
- PK(Primary Key)을 지정하는 Column에 대해 Unique Index(Clustered Index)를 자동 생성
- 적당한 PK(Clustered Index)가 없을 경우 ID 필드를 PK로 설정하고 auto_increament 옵션 사용
-
2. Pros & Cons
- 인덱스를 가지고 Leaf Node까지 탐색해서 원하는 데이터를 바로 얻을 수 있다.
- 인덱스 기준으로 데이터가 함께 정렬된 상태를 유지한다.
- 검색 속도가 빠르다.
- SELECT 외에 작업 수행 시 속도가 느리다.(재배열 필요)
-
3. Architecture
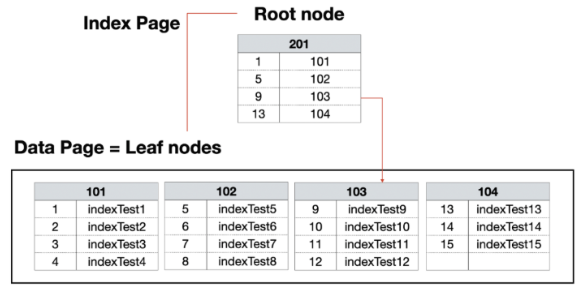
-
4. Search
- Clustered Index Seek
- 탐색 조건에 Index Key로 지정된 Column을 사용하는 경우
- Root 페이지에서 Leaf Level까지 Clustered Index Key를 통해 조건을 탐색하여 검색 경로를 따라 수행한다.
- Index를 타고 특정 범위만 읽어냄(매우 빠름)
- Clustered Index Scan
- 탐색 조건에 Index Key로 지정된 Column을 사용할 수 없는 경우
- Leaf Level의 첫번째 페이지부터 차례로 모든 페이지를 읽는 방법
- Heap의 Table Scan과 비슷하다.
- Clustered Index Seek
Non-Clustered Index
-
1. Features
- 실제 데이터가 저장된 Heap 영역과 별도로 인덱스 페이지를 관리한다.
- Leaf Node에서 인덱스의 RID(ROWID)를 이용하여 실제 데이터가 저장된 Heap 영역에 접근한다.
- 인덱스 페이지만 관리하고 실제 테이블 데이터는 정렬하지 않은 상태를 유지한다.
- 지정된 Column에 대해 여러 개의 인덱스를 생성할 수 있다.
- unique 제약 조건을 설정한 Column에 대해 자동으로 Non-Clustered Index 생성
-
2. Pros & Cons
- 인덱스를 가지고 Leaf Node에 탐색해서 데이터 위치만 얻고 실제 Heap 영역에 접근하여 데이터를 얻는다.
- 인덱스만 정렬되고 실제 데이터는 정렬되어 있지 않다.
- INSERT/UPDATE/DELETE 작업 속도가 빠르다.
- 검색 속도가 느리다.
-
3. Architecture
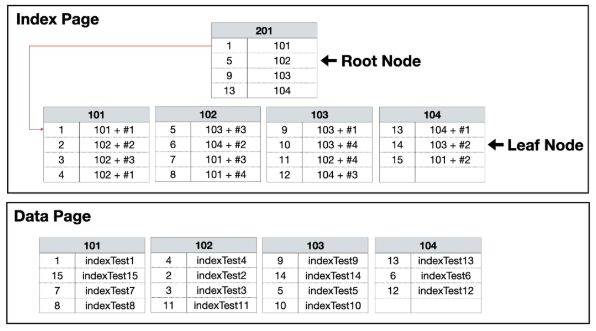
-
4. Combination
- Heap + Non-Clustered Index
- 페이지 모두 읽기 : Table Scan
- Index Key + RID
- RID Lookup : Heap 검색 시에 Non-Clustered의 RID 값을 이용해서 검색한다.
- Clustered Index + Non-Clustered Index
- 페이지 모두 읽기 : Clustered Index Scan
- Index Key + Clustered Index Key
- Key Lookup : Non-Clustered Index가 가지지 못한 데이터를 찾아가는 과정
- Heap + Non-Clustered Index
Reference
- https://shin-bugkiller.tistory.com/42
- https://developers-haven.tistory.com/54
- https://velog.io/@juhyeon1114/MySQL-Index%EC%9D%98-%EA%B5%AC%EC%A1%B0-B-Tree-BTree
- https://developers-haven.tistory.com/55
- https://velog.io/@juhyeon1114/MySQL-Index%EC%9D%98-%EA%B5%AC%EC%A1%B0-B-Tree-BTree
- https://earthteacher.tistory.com/216#gsc.tab=0
- https://wslog.dev/mysql-index
- https://zorba91.tistory.com/293