Scalable Data Streaming Optimization: From Standard I/O to High-Performance NIO Governance
들어가면서
대규모 데이터 처리에서 성능의 핵심은 ‘데이터가 메모리에 머무는 시간을 최소화하고, 이동 횟수를 줄이는 것’입니다. 주니어 개발자가 흔히 사용하는 RestTemplate의 표준 I/O 방식은 사용하기 편리하지만, 내부적으로는 엄청난 양의 메모리 할당과 복사 연산을 수반하며 시스템 자원을 갉아먹습니다.
본 포스팅에서는 데이터 전송의 가장 밑바닥인 Native Memory(JNI) 레벨부터 시작하여, 왜 빅테크 기업들이 WebClient와 NIO를 선택하여 극한의 최적화를 달성하는지 그 물리적 이유를 파헤쳐 봅니다.
1. 물리적 실체: IO와 NIO의 데이터 이동 경로
데이터가 네트워크 소켓에서 우리 서버의 파일 시스템으로 저장되기까지, 메모리 상에서는 어떤 일이 벌어질까요?
1) Standard I/O (RestTemplate + StreamUtils)
표준 I/O의 핵심은 Temporary Buffer과 Heap입니다.
- Native -> Heap -> Native: OS 커널이 데이터를 소켓에서 퍼 올릴 때 JVM은 GC가 건드리지 못하는 임시 Native Buffer(Direct Buffer)를 JNI를 통해 할당합니다.
- 불필요한 복사: 이 임시 버퍼의 데이터를 자바가 읽기 위해서는 반드시 Java Heap(
byte[])으로 값 복사(Memcpy)를 수행해야 합니다. - 할당/해제의 무한 반복: 16KB 데이터를 8KB 단위로 전송할 때 네트워크 수신(2회) + 파일 쓰기(2회) 과정에서 최소 4~6회의 Native Memory 할당과 해제가 발생합니다. 이는 CPU가 데이터를 옮기는 일보다 OS에게 메모리를 빌려달라고 System Call 부하에 더 많은 에너지를 쓰게 만듭니다.
2) NIO (WebClient + DataBufferUtils)
NIO의 핵심은 Buffer Pool와 Zero-copy입니다.
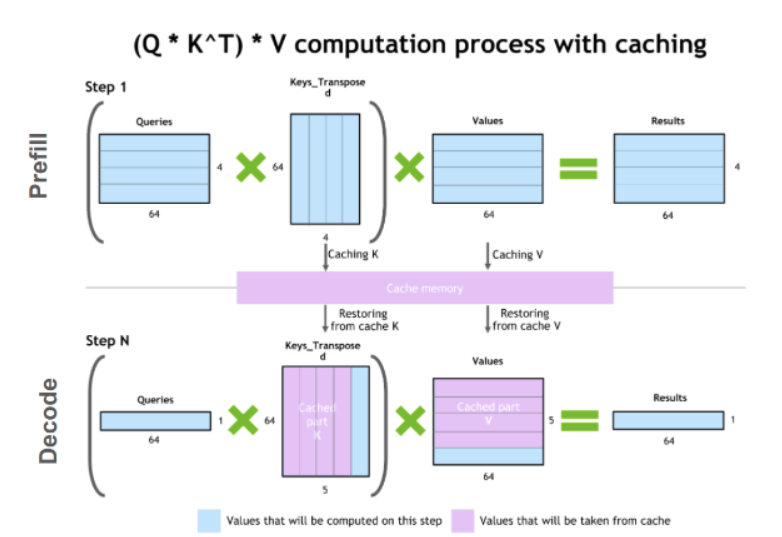
- Native -> Native: 네트워크 소켓에서 담아온 데이터를 굳이 자바 힙으로 옮기지 않습니다. 데이터가 담긴 Native Buffer의 메모리 주소만 파일 시스템(FileChannel)에 넘겨주어 OS가 직접 처리하게 합니다.
- Pooling: 데이터를 담을 바구니를 매번 새로 만들지 않습니다. 미리 할당된 Direct Buffer Pool에서 빌려오고 반납하는 방식을 취합니다.
2. JNI Direct Buffer의 생명주기와 Connection Pool의 오해
주니어 단계에서 가장 많이 혼동하는 지점이 ‘연결 유지(Connection)’와 ‘메모리 재사용(Buffer)’의 차이입니다.
- Connection Pool의 한계:
Apache HttpClient의 커넥션 풀을 쓰면 소켓 통로는 유지되지만 그 안을 흐르는 데이터 바구니는 여전히 일회용입니다. 커넥션이 열려 있다고 해서 버퍼가 계속 살아있는 것이 아니라read()호출 시점에 잠깐 태어났다가 힙으로 복사가 끝나면 그 즉시 파괴(free)됩니다. 연결 통로는 그대로인데 Buffer는 매번 새로 만들어 쓰고 제거합니다. - JNI의 필수성: JVM이 OS와 대화하려면 Direct Buffer는 선택이 아닌 필수입니다. 자바 힙은 GC에 의해 위치가 수시로 바뀌기 때문에 OS 커널에게 고정된 메모리 주소를 제공할 수 있는 Native 영역의 징검다리가 반드시 필요하기 때문입니다.
3. 고성능의 심장: Netty와 PooledByteBufAllocator
WebClient가 RestTemplate보다 압도적으로 효율적인 이유는 하부 엔진인 Netty가 메모리를 다루는 철학에 있습니다.
- Pooled Allocation: Netty는 기동 시 OS로부터 거대한 Native 메모리 영역을 미리 점유(Slab Allocation)합니다.
- DataBuffer의 실체: Spring의
DataBuffer는 사실 Netty가 제공하는ByteBuf의 추상화된 가면입니다.DataBufferUtils를 사용할 때, 우리는 사실 Netty가 관리하는 고정된 Native 주소를 직접 제어하는 것입니다. - 성과: 매 요청마다 발생하던
malloc/free시스템 콜이 거의 0에 수렴하게 되며, 이는 전체 시스템의 Context Switching 비용을 드라마틱하게 낮춰 CPU가 온전히 비즈니스 로직에만 집중할 수 있게 합니다.
4. NIO의 두 가지 필수 조건: 최적화의 완성
단순히 라이브러리를 바꾼다고 NIO 성능이 나오는 것은 아닙니다.
- Off-heap Memory 사용 (Heap 최소화): 데이터가 Java Heap을 거치지 않고 Native 영역(Direct Memory)에서 바로 목적지로 전달되어야 합니다. 이는 GC 부하를 제거하여 STW(Stop-The-World)를 방지합니다.
- Buffer 재사용 (Pooling): 메모리 조각을 매번 생성/파괴하는 것이 아니라 할당된 자원을 대여하고 반납하는 구조를 가져야 합니다. 이를 통해 할당 오버헤드와 메모리 파편화를 방지합니다.
이 두 조건에 Non-blocking 모델이 결합될 때 비로소 적은 수의 Thread로도 수많은 트래픽을 견디는 고성능 시스템이 완성됩니다.
빅테크 시니어 엔지니어로서, 요청하신 대로 5. 실무 적용 섹션을 가독성 높은 텍스트 중심으로 재구성했습니다. 표보다 문장으로 풀어낼 때 각 기술적 선택이 가져오는 원인과 결과(Cause & Effect)가 더 명확히 드러나기 때문에, 논리적인 설득력이 훨씬 강해질 것입니다.
수정된 마크다운 전문을 확인해 보세요.
Markdown
title: “Scalable Data Streaming Optimization: From Standard I/O to High-Performance NIO Governance” excerpt: “[Advanced Theory] JNI Direct Buffer의 물리적 실체부터 WebClient/Netty의 Zero-copy 아키텍처 분석까지” date: 2026-01-11 categories: [Java, Backend, Infrastructure] tags: [RestTemplate, WebClient, NIO, DirectBuffer, JNI, Netty, ZeroCopy, MemoryManagement] —
들어가면서
대규모 데이터 처리에서 성능의 핵심은 ‘데이터가 메모리에 머무는 시간을 최소화하고, 이동 횟수를 줄이는 것’입니다. 주니어 개발자가 흔히 사용하는 RestTemplate의 표준 I/O 방식은 사용하기 편리하지만, 내부적으로는 엄청난 양의 메모리 할당과 복사 연산을 수반하며 시스템 자원을 갉아먹습니다.
본 포스팅에서는 데이터 전송의 가장 밑바닥인 Native Memory(JNI) 레벨부터 시작하여, 왜 빅테크 기업들이 WebClient와 NIO를 선택하여 극한의 최적화를 달성하는지 그 물리적 이유를 파헤쳐 봅니다.
1. 물리적 실체: IO와 NIO의 데이터 이동 경로
데이터가 네트워크 소켓에서 우리 서버의 파일 시스템으로 저장되기까지, 메모리 상에서는 어떤 일이 벌어질까요?
1) Standard I/O (RestTemplate + StreamUtils)
표준 I/O의 핵심은 ‘일회용 쟁반(Temporary Buffer)’과 ‘중간 기착지(Heap)’입니다.
- Native -> Heap -> Native: OS 커널이 데이터를 소켓에서 퍼 올릴 때, JVM은 GC가 건드리지 못하는 임시 Native Buffer(Direct Buffer)를 JNI를 통해 할당합니다.
- 불필요한 복사: 이 임시 버퍼의 데이터를 자바가 읽기 위해서는 반드시 Java Heap(
byte[])으로 값 복사(Memcpy)를 수행해야 합니다. - 할당/해제의 무한 반복: 16KB 데이터를 8KB 단위로 전송할 때, 네트워크 수신(2회) + 파일 쓰기(2회) 과정에서 최소 4~6회의 Native Memory 할당과 해제가 발생합니다. 이는 CPU가 데이터를 옮기는 일보다 OS에게 메모리를 빌려달라고 소리치는 System Call 부하에 더 많은 에너지를 쓰게 만듭니다.
2) NIO (WebClient + DataBufferUtils)
NIO의 핵심은 ‘공유 웅덩이(Buffer Pool)’와 ‘주소 참조(Zero-copy)’입니다.
- Native -> Native: 네트워크 소켓에서 담아온 데이터를 굳이 자바 힙으로 옮기지 않습니다. 데이터가 담긴 Native Buffer의 메모리 주소만 파일 시스템(FileChannel)에 넘겨주어 OS가 직접 처리하게 합니다.
- Pooling: 데이터를 담을 바구니를 매번 새로 만들지 않습니다. 미리 할당된 Direct Buffer Pool에서 빌려오고(Borrow) 반납(Return)하는 방식을 취합니다.
2. JNI Direct Buffer의 생명주기와 Connection Pool의 오해
주니어 단계에서 가장 많이 혼동하는 지점이 ‘연결 유지(Connection)’와 ‘메모리 재사용(Buffer)’의 차이입니다.
- Connection Pool의 한계:
Apache HttpClient의 커넥션 풀을 쓰면 소켓 통로는 유지되지만, 그 안을 흐르는 데이터 바구니는 여전히 일회용입니다. 커넥션이 열려 있다고 해서 버퍼가 계속 살아있는 것이 아니라,read()호출 시점에 잠깐 태어났다가 힙으로 복사가 끝나면 그 즉시 파괴(free)됩니다. 즉, 연결 통로는 그대로인데 수레(Buffer)는 매번 새로 만들어 쓰고 폐차시키는 꼴입니다. - JNI의 필수성: JVM이 OS와 대화하려면 Direct Buffer는 선택이 아닌 필수입니다. 자바 힙은 GC에 의해 위치가 수시로 바뀌기 때문에, OS 커널에게 고정된 메모리 주소를 제공할 수 있는 Native 영역의 징검다리가 반드시 필요하기 때문입니다.
3. 고성능의 심장: Netty와 PooledByteBufAllocator
WebClient가 RestTemplate보다 압도적으로 효율적인 이유는 하부 엔진인 Netty가 메모리를 다루는 철학에 있습니다.
- Pooled Allocation: Netty는 기동 시 OS로부터 거대한 Native 메모리 영역을 미리 점유(Slab Allocation)합니다.
- DataBuffer의 실체: Spring의
DataBuffer는 사실 Netty가 제공하는ByteBuf의 추상화된 가면입니다.DataBufferUtils를 사용할 때, 우리는 사실 Netty가 관리하는 고정된 Native 주소를 직접 제어하는 것입니다. - 성과: 매 요청마다 발생하던
malloc/free시스템 콜이 거의 0에 수렴하게 되며, 이는 전체 시스템의 Context Switching 비용을 드라마틱하게 낮춰 CPU가 온전히 비즈니스 로직에만 집중할 수 있게 합니다.
4. NIO의 두 가지 필수 조건: 최적화의 완성
단순히 라이브러리를 바꾼다고 NIO 성능이 나오는 것은 아닙니다. 엔지니어링 관점에서 다음 두 조건이 충족되어야 합니다.
- Off-heap Memory 사용 (Heap 최소화): 데이터가 Java Heap을 거치지 않고 Native 영역(Direct Memory)에서 바로 목적지로 전달되어야 합니다. 이는 GC 부하를 제거하여 STW(Stop-The-World)를 방지합니다.
- Buffer 재사용 (Pooling): 메모리 조각을 매번 생성/파괴하는 것이 아니라, 할당된 자원을 대여하고 반납하는 구조를 가져야 합니다. 이를 통해 할당 오버헤드와 메모리 파편화를 방지합니다.
이 두 조건에 Non-blocking(비차단) 모델이 결합될 때, 비로소 적은 수의 Thread로도 거대한 트래픽을 견디는 고성능 시스템이 완성됩니다.
5. 실무 적용: IO vs NIO 리소스 거버넌스 분석
프로젝트 설계 시 어떤 기술 스택을 선택하느냐에 따라 시스템 하부의 리소스 사용 효율은 극명하게 갈립니다. 두 진영의 차이를 핵심 아키텍처 관점에서 분석합니다.
1) IO 진영 (RestTemplate + StreamUtils)
- 메모리 할당 모델: 데이터의 매 루프(Loop)마다 시스템 레벨의
malloc과free가 일회성으로 발생합니다. 이는 메모리를 ‘소모품’으로 취급하는 구조입니다. - 데이터 이동 경로: Native 영역과 Java Heap 사이의 불필요한 값 복사가 최소 2회 이상 발생합니다. CPU는 데이터를 처리하는 시간보다 옮기는 시간에 더 많은 자원을 소모합니다.
- 리소스 관리 특징: JVM JNI가 내부에서 자동으로 처리하는 것처럼 보이지만 잦은 할당으로 인해 메모리 파편화와 GC 지표의 불안정성을 초래합니다.
- 성능 임계치: Blocking 모델과 결합되어 Throughput 한계가 명확하며 대용량 트래픽 시 시스템 부하가 급증합니다.
2) NIO 진영 (WebClient + DataBufferUtils)
- 메모리 할당 모델: 기동 시 미리 확보된 Buffer Pool에서 메모리를 대여하고 반납하는 재사용 구조를 가집니다. 신규 할당 비용을 0에 가깝게 유지합니다.
- 데이터 이동 경로: Native 영역에서 데이터를 직접 처리하는 Zero-copy를 지향합니다. Java Heap으로의 복사를 생략하여 CPU 효율을 극대화합니다.
- 리소스 관리 특징: Reference Counting을 통한 정교한 수동 관리가 필요합니다. 이는 개발자가 메모리의 수명주기를 완벽히 통제함을 의미합니다.
- 성능 임계치: Non-blocking 모델을 통해 Thread당 처리 효율을 극대화하며 대규모 자원을 일관성 있고 안정적으로 유지할 수 있습니다.